
Does AI speed up research?
A closer look at the five stages of speedup: Research taste remains the bottleneck for now


This post was co-authored with Sanjana Iyer.

Researchers in Zurich have created fully AI-generated research papers. Does this imply that AI will take over research? And what does the success of AlphaFold really tell us about the future of research?
AI will speed up some parts of research, especially experimentation, data analysis, and writing. But the gains might not speed up research because research taste is a bottleneck to faster progress. Research productivity has been declining for decades, even as the number of researchers has been rising, while the growth rate has remained constant. AI doesn’t replace researchers, but the grunt work of research assistants (like us), especially in data analytics and experimentation. Leopold Aschenbrenner described GPT-4 as a smart high-schooler in Situational Awareness; current AI is more of a smart research assistant than a PhD holder.
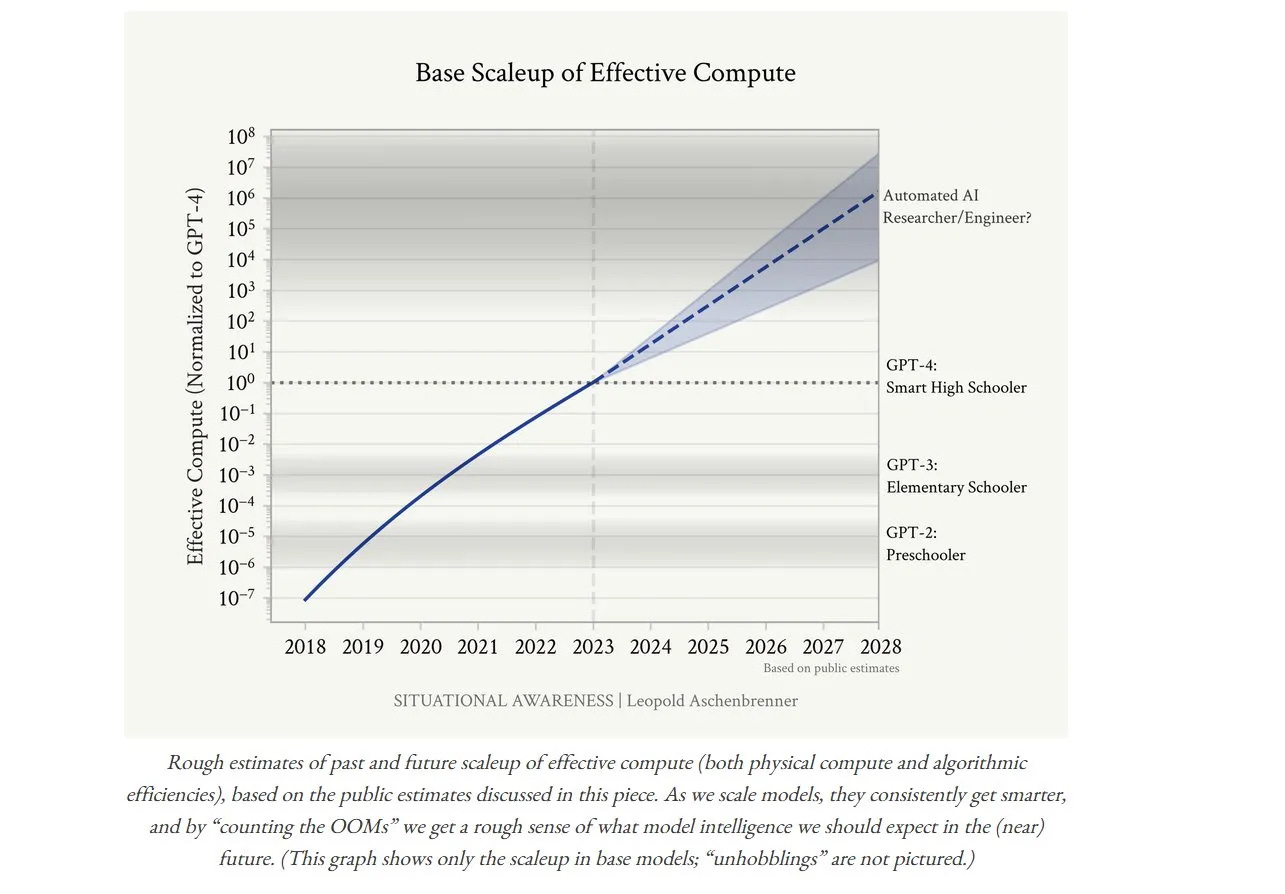
Current AIs are orders of magnitude larger than ChatGPT and still can’t automate researchers. Situational Awareness might have been lacking among research assistants among high schoolers and senior researchers.
We will examine the five complementary stages of empirical research in chronological order and analyze AI’s impact step by step.
Research Taste
“Taste” has been the word of the hour in Silicon Valley, as even the New Yorker from the East Coast reports. AI labs are trying to instill it in their models, while AGI-pilled tech workers rely on their taste to feel secure against the wave of AI automation they foresee. But is ideation - as old-school researchers might call it- really the bottleneck for advancing research?
The physicist Richard Hamming famously asked his colleagues what they were working on and what the most important problem in the field was. In a talk, he points out that not raw intelligence, but courage and aesthetic vision are essential for groundbreaking research. Research taste here is a multidimensional task that is hard to replicate or teach.
Hamming deviates from popular combinatorial ideas of idea generation. AIs have solved math problems in innovative ways and have more novel ideas in board games like chess and Go. This combinatorial approach, in which AI synthesizes and identifies links, has so far failed to generate new solutions to ambiguous problems.
Another approach to research taste is more prevalent today. The DeepMind ML researcher Neel Nanda1 defines research taste in a more empirical, less essentialist way: training data and sample efficiency are the most important ingredients for asking good research questions. He also breaks down research taste into System 1 intuition and System 2 conceptual frameworks. System 1 leads researchers to ask, “This anomaly seems important“, while system 2 requires deep domain knowledge to generate hypotheses, evaluate plausibility explicitly, and explain why your intuition feels a certain way.
While AI has access to lots of unstructured training data, AI has limited research taste. Creating training environments for research ideation is tough because researchers can’t reinvent the tech tree in an RL environment.
At a macro level, ideas have been getting harder to find for humans. While research productivity has fallen dramatically, the number of human researchers has grown dramatically to counterbalance the trend. Research is also probably not parallelizable, because doubling the number of researchers doesn’t double research output, since research taste differs dramatically between top and marginal researchers due to power-law dynamics. That the lowest-hanging fruits have been taken suggests that research taste and experimenting - or sample efficiency and training data, as Nanda might say - are even more important.
A recent model of AI R&D by Tom Cunningham and Manish Shetty from the AI evaluation nonprofit METR takes the apple picking seriously and applies it to AI agents:
The model takes the metaphor literally: an AI agent helping you to optimize an algorithm is like a robot helping you pick apples. It will take care of all the apples up to a certain height, and it may find apples you haven’t found yet, but there will still be apples out of its reach.
The model implies that agents can push the frontier forward, but the returns will sharply diminish. It also implies we can measure an agent’s ability with a human-equivalent time horizon, e.g., as of March 2026 agents seem to be able to find optimizations on frontier algorithms worth about 1 week of professional human labor, yet those effects are not additive.1 You can’t get two weeks’ labor by running an agent twice.
The basic ideas can all be seen in the drawing below. Here the human and robot are both picking trees. The robot is cheaper to run, but it can only reach the low apples. In the illustration, they have both picked 4 apples, yet left the tree in a very different state, such that the robot isn’t ready to replace the human yet:
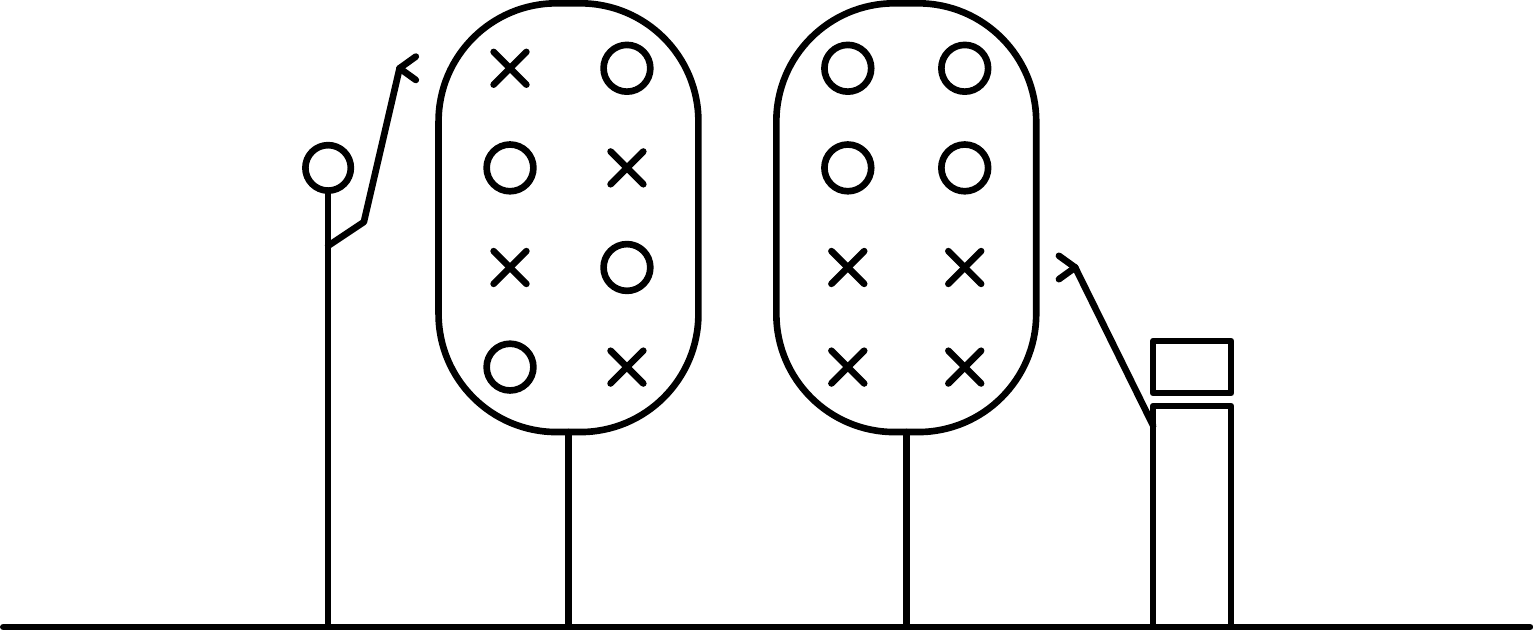
This implies that AI lacks the taste to find groundbreaking ideas.
Overall, this makes us skeptical that AIs can automate research. We believe, like Hamming, that original research ideas are hard to automate. AI agents might only help us find all the low-hanging fruit through extended experimentation. While it’s quite likely that the idea can generate more low-hanging fruit, high-hanging fruit outside easily verifiable domains, such as math, are less likely and remain the largest bottleneck for AI in speeding up research.
Data & analysis
Coding tools like Claude Code have revolutionized research, with revenues skyrocketing and huge increases in related benchmarks. They’re especially useful for data analysis, where researchers analyze data or results in a mostly quantitative manner. Most modern data analysis is done with programming languages such as Stata, R, and Python, in which AI has made huge progress. But researchers on their journey to new frontiers of knowledge need to be aware of some lurking icebergs.
A 2025 study claiming that AI would slow down software engineers made waves. It showed that experienced open-source developers were slowed down by AI in their codebases.
A follow-up study using newer models showed that more participants dropped out due to the costs of forgoing AI assistance. Together with the rising benchmark performance, it indicates the growing importance of software tasks
These software engineering results are highly relevant for data analytics. Both can be performed in coding languages, whether statistical ones like R or general-purpose ones like Python. The context in a codebase is comprehensive, and the outputs are verifiable. Coding benchmarks like SWE-bench Verified have seen the largest gains. There are also additional data analytics-relevant benchmarks, such as InfiAgent-DABench, which is specifically designed to evaluate LLMs on end-to-end data-analysis questions spanning task planning, code generation, execution, self-debugging, and conclusion derivation. This comprehensive data analysis benchmark seems saturated and no longer reports results for the newest models.
AI helps in all parts of data analytics, not just code generation. The planning mode of coding agents also handles rigorous planning. With modular coding methods and extensive automated testing, as advocated by the creator of Claude Code, Boris Cherny, coding agents’ self-debugging capabilities can be significantly improved.
Nonetheless, deriving conclusions and debugging at the highest level require some form of human participation, for reasons discussed in the previous section. Some MIT researchers theorize that verification remains the bottleneck as AI becomes more intelligent, while verification improves more slowly. Measurable domains, such as data analytics, are increasingly dominated by AIs.
Regarding data analytics, AI is best thought of as a skilled research assistant that needs clear instructions and verification.2 These can speed up the research in data-heavy domains, but these are not the ones driving innovation.
Our own experiences as research assistants confirm AI’s impact in data analytics. While our headcount might be slightly falling, we benefit from less grunt work. We believe AI is expertise-raising for research assistants, that debugging and preliminary conclusions from data are becoming larger parts of the field. Jacob, for example, is trying to harness the reduced barriers to research by analyzing the data himself and proposing next steps based on it. That could help generate the senior judgment skills and research taste that senior researchers still uniquely possess more quickly.
Experimentation
If we define experimentation as the process of testing hypotheses to draw evidence-based conclusions, it tends to look quite different across disciplines. In the hard sciences such as physics, biology, and chemistry, these experiments operate at the physical level. You’re testing the laws of nature in controlled environments, think dropping balls from buildings and mixing liquids in test tubes. Whereas in the field of social sciences, we’re examining behavior and people, this could look like psychological experiments (e.g., the Stanford Prison experiment) or the randomization of microloans in villages. Physical experimentation with humans has several costs, including time and ethical issues, so social scientists often turn to quasi-experimental techniques to test their hypotheses using data. Then fields like philosophy and maths don’t really have experimentation in the same way, but knowledge grows from arguments and proofs.
The naive expectation is that AI has little to offer physical experimentation, but this turns out to be wrong. However, what’s quite interesting is that AI is strongly influencing the experimentation layer in the hard sciences, and one incredible example is the new AI tools in generative biology.
One of the major challenges in biology was protein folding. A protein is a chain of amino acids that folds into a specific 3D shape, and that shape determines its function, such as binding to a virus or signaling in a cell. We want to design proteins to perform specific functions, so we can build custom proteins to create targeted drugs or enzymes. The hard part is that the space of possible protein designs is unimaginably vast (20³⁰⁰ for a modest-length chain), and until recently, the only reliable way to know what shape a sequence would fold into was to make it in a lab and look. This meant that protein design for a specific function involved searching a near-infinite space with a tool that took months per guess.
CASP, a competition since 1994 where the organizers release a 1D amino acid sequence to the world, and labs race to try and predict the full range of 3D structures it could fold into. Once the submissions come in, the real structures are released, and the predictions are scored for accuracy. For reference, top scores in the 2010s were around 60% accuracy. In 2020, DeepMind’s tool AlphaFold2 averaged in the high 80s to low 90s. The shift was so striking that the problem they’d organized the competition around was essentially solved.
What does this mean for biological experimentation? Within a year, AlphaFold2 structures were being used as starting models for crystallography, as scaffolds for protein design, as a way to triage which experiments were even worth running. As of 2020, there were around 170,000 experimentally solved protein structures worldwide, representing 50 years of cumulative effort. There are now over 200 million predicted structures. It’s important to note that this AI tool didn’t really change or edit the actual wet-lab process of expressing these proteins, but it made it magnitudes easier to determine which proteins were likely to succeed, even before reaching the lab. Now there are new tools that help this process, like RFDiffusion and PROTEINmpnn, which take you in the other direction from functions and 3D structures to 1D amino acid sequences, too. We are confident that AI is reducing repetition and uncertainty in scientific experimentation. We expect the AlphaFolds of physics and chemistry to succeed because both fields have a large, deterministic, and verifiable search space for experimenters to research.
AI has the potential to speed up experimentation, since AlphaFold shows that the long loop of running experiments is increasingly being run on GPUs.
What about the social sciences, however? It’s not exactly shocking that AI can do quasi-experimental analysis. Quantitative social science is largely about data, so this feels natural. An interesting demonstration of this capability is Project APE, out of the Social Catalyst Lab at the University of Zurich, where AI agents run the entire observational research pipeline end-to-end. They pick a policy question, pull real data from public APIs, run the econometrics, and write the paper. The more interesting case, in my opinion, is whether AI can help us with the toughest form of social science experimentation: testing how real people respond in the real world. One example we see of an AI tool trying to substitute for this is simile.ai, a startup building simulations of human populations using generative agents grounded in real people’s lives. The key finding from their foundational paper is that agents constructed from interviews with 1,052 participants reproduced those individuals’ General Social Survey answers with roughly 85% of the accuracy the participants themselves achieved when retaking the survey two weeks later. It sounds incredibly exciting to be able to have a little sandbox to rehearse, say a policy rollout, replay it under different conditions, and surface outcomes that no actual experiment could ethically produce. AI will likely be able to perform pilot studies.
The larger impact of AI so far on biology than on the social sciences also illustrates the differential impact AI will have on different disciplines.
The obvious pushback is whether any of this is trustworthy. It’s one thing to predict how someone fills out a survey; it’s another to predict how an entire population reacts to a new tax over five years, with all the messiness and feedback loops that entail. Regardless, it’s quite exciting for social scientists and still pushes the same idea. AI probably isn’t substituting for the gold-standard experiment, but is promisingly shaping which experiments are worth doing and giving us predictions about how they’d likely play out.
Writing
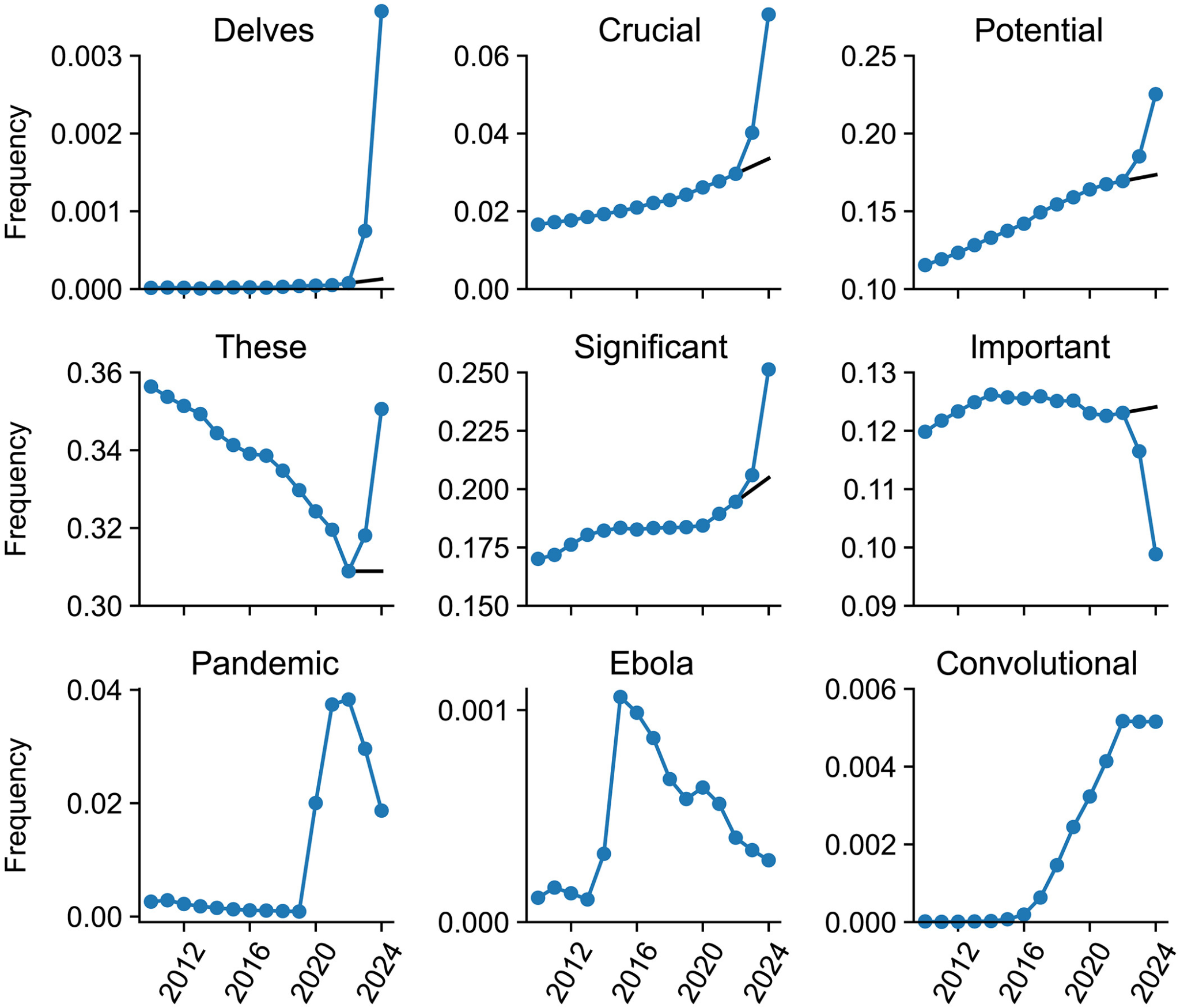
How AI changed the word frequencies in published papers according to Kobak et al.
Writing is likely the step of the process where the impact is relatively homogeneous across disciplines. Kobak et al.‘s analysis of 15M PubMed abstracts identified 379 stylistic words with sharply elevated 2024 frequencies (such as delves, meticulous, commendable), and Picazo-Sanchez and Ortiz-Martin estimate LLM involvement in roughly 10% of papers across 300 journals. So it’s clear that AI is being used to write up research, but what are the consequences of this?
Our take is that this doesn’t affect the quality of research produced, modestly speeds up research timelines, and helps non-English-speaking researchers. The bottleneck on a paper’s quality is the underlying experiment, the data, the argument, not the prose. A weak study written in beautifully polished AI-assisted English is still a weak study, and a strong study in awkward prose is still a strong study. If anything, faster writing might free up more time for the parts of research that actually matter.
The largest benefit we see is that it speeds up research timelines in a fairly mundane but tangible way: drafting an introduction, restructuring a discussion section, or polishing a methods paragraph are all things that used to eat days and now take hours.
One equitable impact is that it dramatically lowers the cost of publishing in English for researchers whose first language isn’t English. The current academic system effectively imposes a writing-fluency tax on the global majority of researchers, and LLMs are the closest thing we’ve had to a real fix for that. In the Picazo-Sanchez and Ortiz-Martin study, the countries with the highest rates of LLM-detected publications were predominantly those that don’t have English as an official language. A separate dermatology-focused study comparing JAAD Research Letters articles from 2020 and 2024 found a clear rise in AI-assisted writing among non-native English authors, with no comparable shift among US authors.
The strongest objection to the point that writing is not a proxy for good research is that language is a signal. Reviewers use writing quality as a proxy for the writer’s clarity of thought, and a paper that’s well-organized, precise, and free of clunky phrasing reads as more rigorous. If LLMs flatten everyone’s prose to the same competent baseline, that signal collapses, and we lose a filter that did some work in distinguishing careful researchers from sloppy ones. We think this filter was mostly noise, though, and what it mostly tracked was time, money, and native-language privilege, not rigor.
Publication
The average peer-review time now exceeds 100 days, and some journals take more than six months from submission to decision. Around 3.4 million scientific papers were published in 2025, against a reviewer pool that hasn’t grown anywhere near as fast, and over 70% of scholars decline review invitations because the article doesn’t match their specialism, and 42% feel overwhelmed by other commitments. If AI helps this review process, it would solve a major problem in this step of the research.
Refine.ink is a technical verification tool that returns reviewer-grade feedback on most papers in 20–40 minutes for $50 and catches subtle issues that would take a human expert hours to identify. Does the maths work? Do the cited papers actually say what’s claimed? Are the figures consistent with the tables, so the human reviewer can focus on novelty and judgment? Users on X and reviews on the website seem to be overwhelmingly positive about it. This dramatically increases the amount of review papers received, as the real bottleneck for reviewers is attention. It might also simplify review by AI agents, automatically reproducing results when fed with the paper and the data.
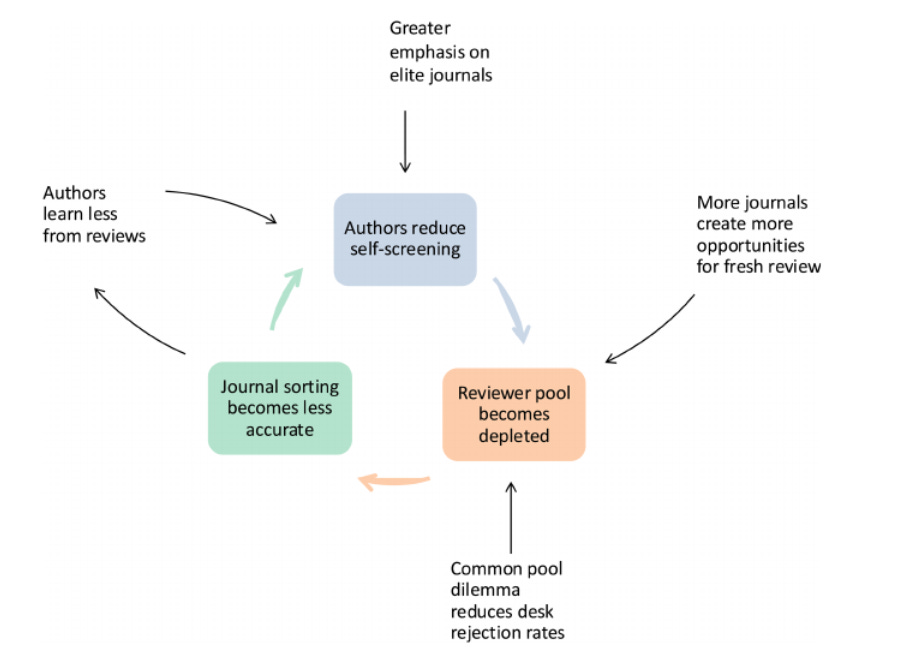
The meltdown of peer review is illustrated for anybody who hasn’t heard horror stories on X.
But AI hits this loop from both sides. The cost of producing a submittable-looking paper has collapsed at the same time as the cost of reviewing one, and the two effects compound in a particular direction. Bergstrom and Gross formalize this in their “peer-review meltdown cycle”: more submissions exhaust the reviewer pool, reviews get less accurate, and noisier reviews encourage even more authors to try their luck at venues that might otherwise be a stretch. Once the submission cost is low enough, journals are flooded because the system reaches a point where all authors submit regardless of quality. So even if Refine and tools like it cut review time in half, the volume of submissions can rise faster, and the reviewer pool stays the same finite human resource it always was.
AI accelerates both sides of the publication bottleneck, but not in equal measure. Writing a submittable paper is an individual task that AI can optimize directly; reviewing requires matching domain expertise, maintaining independence, and coordinating across a finite pool of qualified humans. The cost of producing might fall faster than the cost of filtering.
Of the steps in the pipeline, this is the one where we’re least confident that things end well. Writing and experimentation are problems that AI can solve for individuals; publication is a coordination problem in which individual gains create collective costs. Whether this happens is a question about gatekeeping, not about models.
Research taste as the weak link of the research stages
Research taste remains the main bottleneck for now, while AI helps a lot with experimentation. It speeds up research assistants much more than senior research taste. Of the five stages, research taste is where AI contributes least, making it the binding constraint on how much AI can accelerate research overall. We see AI as an expertise-raising technology for junior researchers: It shifts them to more senior tasks, because data cleaning and analysis are taken over by coding agents. This changes who gets to become a researcher and how: Demonstrating some kind of independent research projects has become easier with AI, as RAs and demonstrated research taste become more important. The returns to original research will keep rising for now. Maybe researchers face the same changes from AI like other workers: Seniority-biased technological change that rewards research taste over data analysis.
His definition of research stages is closely related to ours.
 | A guest post by
|